The study course that I’m taking for my AWS Solutions Architect Assoc. exam has quizzes at the end of each topic, and I was doing really well until I took the quiz for EBS, and failed. In my experience, EBS hasn’t been something I have spent a lot of time on, and have only understood at a high level. EBS is very customizable based on your use cases, and it is also very tightly coupled with other functionality within EC2, so it’s important to understand what it’s capable of.
Creating a Volume
The first thing you see when creating a volume under the “Create volume” header is- “Create an Amazon EBS volume to attach to any EC2 instance in the same Availability Zone”. This is really important, you cannot have an EBS volume in a different availability zone as the EC2 instance. Moving on from that, we will look at customizing the Volume settings.
Volume Types
SSD
At a high level, EBS offers SSD and HDD volume types. By default, EBS selects “General Purpose SSD (gp2)”, which is good for developing, testing and boot volumes. In the AWS docs, they say “we recommend these volumes for most workloads”. There is also a “gp3” volume type, which is the improved version of gp2. These are scalable and pretty cost effective, but are not really appropriate for applications that are super latency sensitive or have high throughput needs.
If you have high throughput intensive workloads and high performance, low latency needs, then the “Provisioned IOPS SSD (io1)” volume type is a better fit. This is the highest performance option of all the storage volumes, but it is also the most expensive. There is also an “io2” volume type, which is the newer version of the io2. With the io1 volume type, you can actually specify the IOPS you want the volume to be able to handle per second.
HDD
In terms of the hard disks there are two types: “Cold HDD (sc1)” and “Throughput Optimized HDD (st1)”. The sc1 volume type is the cheapest option, and it’s good for infrequently accessed data. The st1 volume is great for frequently accessed, high throughput workloads. The Amazon docs recommend this volume type for “ETL, data warehouses, and log processing”. Keep in mind that HDD volumes cannot be used for the boot volume.
Instance Store Volumes
After going through the volume types and hearing about what can or can’t be a root volume, it had me wondering, “where and how do you configure the root volume?”. I had a suspicion that you have to choose the boot volume when you configure the EC2 instance, which is correct. By default, you will see an EBS Volume on the instance in the Storage section:
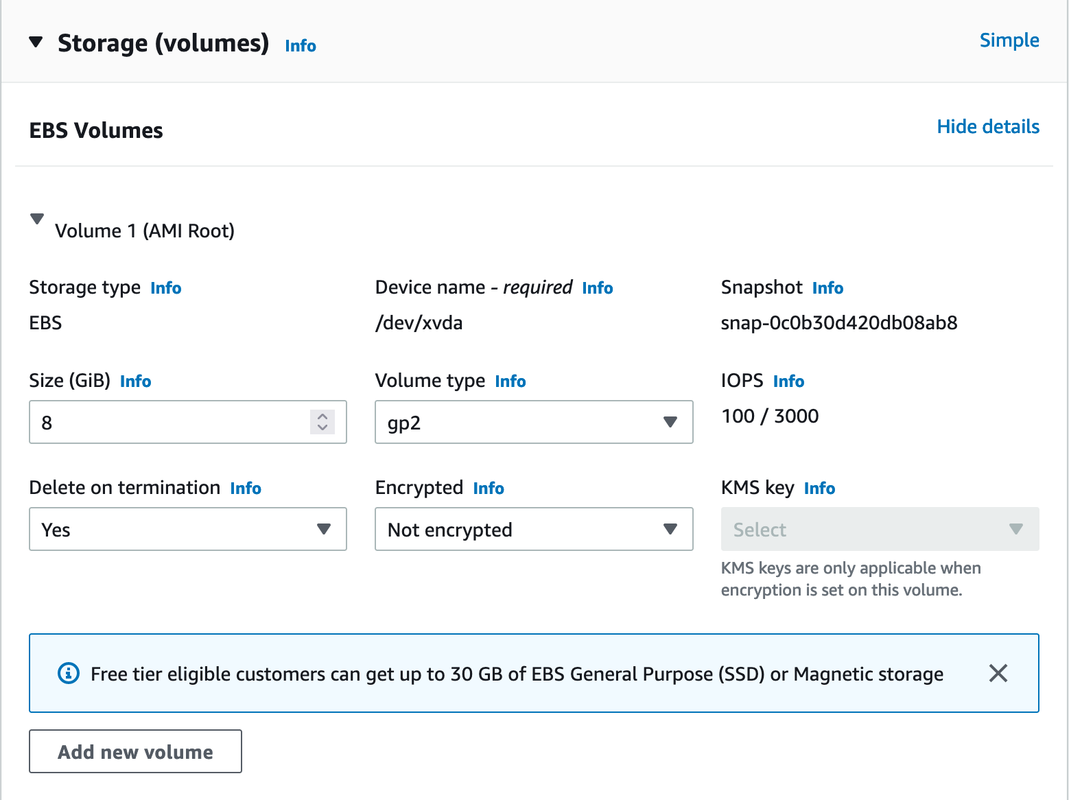
What’s a little tricky about this is that it actually comes from the Amazon Machine Image (AMI) that is chosen at the top in the “Application and OS Images section”. It clearly states under the section title “An AMI is a template that contains the software configuration (operating system, application server, and applications) required to launch your instance”.
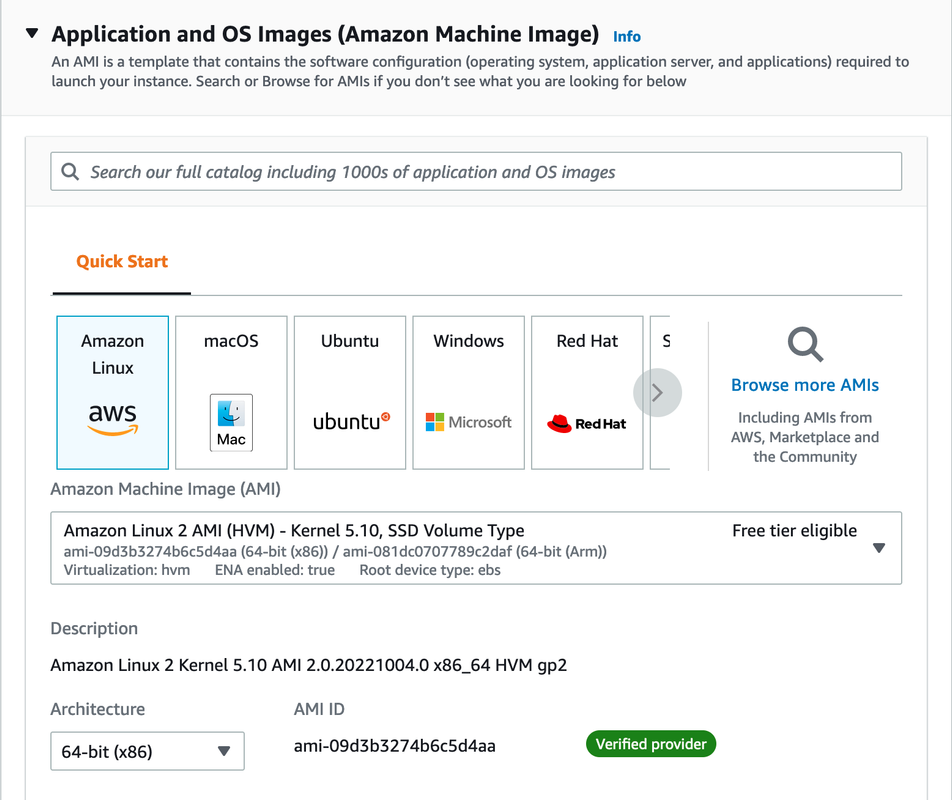
If you look closely you will see “Root device type: ebs”, which explains where we are getting that default EBS boot volume. Another option would be to use an Instance Store volume if you need temporary storage and do not care to lose what’s on the volume after the lifecycle of the instance. One nuance here is that you cannot stop an EC2 instance if it has an Instance Store attached to it, it can only be terminated, in which you lose the volume.
AZs, Encryption and Snapshots
As we saw earlier, we have to place the EBS volume in the same availability zone as the EC2 instance we want to attach it to so keep that in mind when selecting an Availability Zone. Then we have “Snapshot ID” as an optional choice. We can create a snapshot of an EBS volume as a point in time copy of the volume, and then use that to create new EBS volumes, so that is an option. AWS actually provides a number of public snapshots that are available for anyone to use. Then there is a box to check to encrypt the volume. We can encrypt an unencrypted volume after it’s been created through the use of snapshots, which I will probably cover in another post.
IOPS and Throughput
After sitting through the course I’m taking and reading a lot of AWS documentation, it’s occurred to me that I’ve become numb to the words IOPS and throughput and seems to conceptualize them as the same thing, but they are not. IOPS stands for “input/ output operations per second”, which is basically a measure of the reads/ writes per second on disk. I’m thinking of lots of small fast, transactional types of things for IOPS. Throughput is the number of bits that it can read/ write per second, so basically the amount of data that can be processed over time. This pertains to things like big data, when I think throughput I’m thinking “move as much of it as fast as possible”. Breaking these two terms apart was really challenging for me to wrap my head around, and I think in certain situations it can still trip me up, but in general this is how I think of it.