Lately I’ve spent some time exploring Amazon’s Redshift Data API tool, and I have to say, I’m loving it. Not only have I found the Data API easy to use, but I think it’s also an appropriate solution for all kinds of data problems. I wanted to layout some documentation I have found really useful and walk through the basics of interacting with the Data API.
What is the Redshift Data API?
The Redshift Data API is an API that allows you to interact with a Redshift instance. It basically acts as a bridge between your application or another AWS service and Redshift and allows you to query Redshift, as if you were querying it directly. The API calls return response objects that give more information about the status of the requests, and the query running in Redshift.
Trying out the Redshift Data API
I put together a simple tutorial on how you can use the Redshift Data API in Python. Boto3 is the Amazon SDK for Python and the documentation will undoubtedly be your friend. I find the docs very comprehensive, and the examples are great. I have also tried out the Redshift Data API with Ruby and the SDK documentation is also very good.
Setting up Redshift
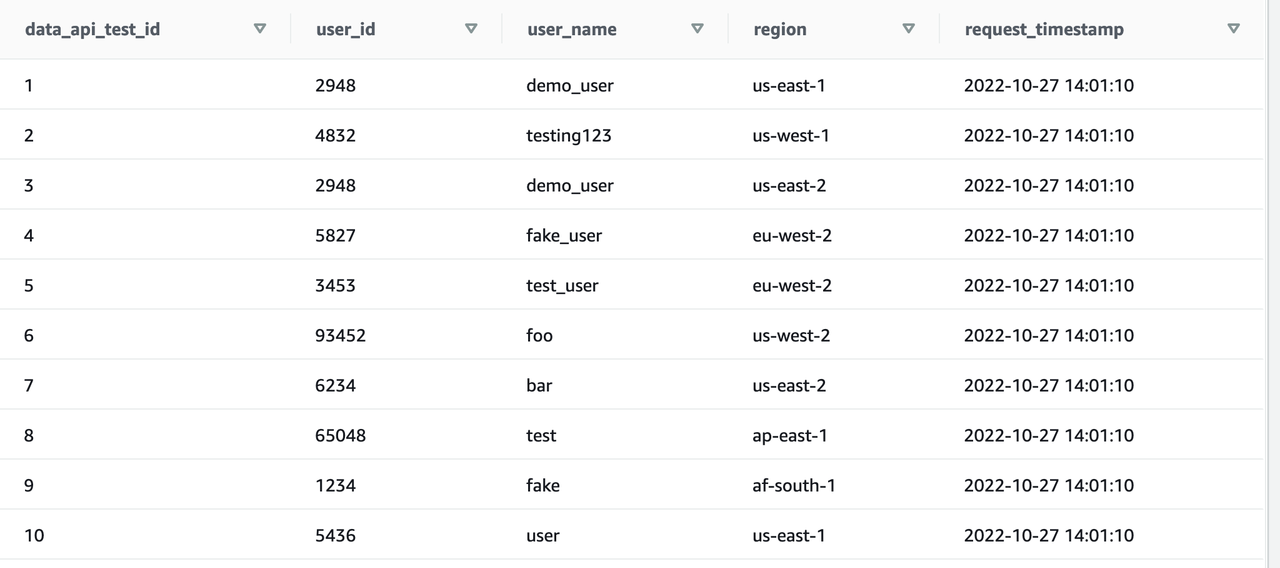
I created a Redshift instance in my AWS account and wrote a data setup file, which includes some basic SQL statements to create a table in Redshift and load some test data into the table. Here’s what the test data set looks like:
select *
from demo.data_api_test;
Using the Data API
If you check out the Boto3 docs, you’ll see there are a lot of API calls you can make against the Redshift Data API, but I’m just going to go over the ones I’ve found the most useful. The first thing you need to do is add the boto3 import, so we can use the library:
import boto3
From there we need to set up a client object to use the Redshift Data API. The first parameter the Boto3 client takes is the AWS service name, and the second is the region. I’ve noticed in the docs the examples don’t require the “region” parameter, but I’ve found that it is necessary and fails without it:
client = boto3.client('redshift-data', 'us-east-1')
Now that the client is set up, we can start making API calls to Redshift. In order to make the API call to kick off the query against Redshift, I’m going to use the execute_statement() call. This API call takes the cluster and database connection information, as well as the sql query to run against Redshift:
execute_stmt_resp = client.execute_statement(
ClusterIdentifier='redshift-cluster-1',
Database='dev',
DbUser='awsuser',
Sql='select * from demo.data_api_test'
)
There are other parameter options that can be added to this depending on the use case, but these are the ones I’ve been using that get the job done. It’s important to save the response object that we get back from the API because it contains an UUID that is unique to the query, and it’s needed in subsequent API calls to check the query status, get the query results, etc. This UUID can be used to make additional API calls for up to 24 hours. Here is the response object we got back from the execute_statement() call above in the form of a dict:
{'ClusterIdentifier': 'redshift-cluster-1', 'CreatedAt': datetime.datetime(2022, 10, 27, 15, 20, 9, 800000, tzinfo=tzlocal()), 'Database': 'dev', 'DbUser': 'awsuser', 'Id': '61e30b26-8398-4aca-95d6-306ff1e7298e', 'ResponseMetadata': {'RequestId': 'cd1958d6-0812-4515-8365-50a86641535d', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': 'cd1958d6-0812-4515-8365-50a86641535d', 'content-type': 'application/x-amz-json-1.1', 'content-length': '149', 'date': 'Thu, 27 Oct 2022 21:20:09 GMT'}, 'RetryAttempts': 0}}
After executing the statement we want to check on the status of the query using the describe_statement() API call. Depending on how busy the Amazon cluster is, it might take a little time for the query to execute, and it will likely return with a status of “PICKED” or “STARTED”. The DescribeStatement API reference has all the different statuses it could bring back and their meanings. Since I just created the Redshift cluster specifically for this demo, it should finish almost immediately:
desc_stmt_resp = client.describe_statement(
Id='61e30b26-8398-4aca-95d6-306ff1e7298e' # this is the Id from the execute_statement() call
)
The response looks like:
{'ClusterIdentifier': 'redshift-cluster-1', 'CreatedAt': datetime.datetime(2022, 10, 27, 15, 20, 9, 800000, tzinfo=tzlocal()), 'Duration': 50449917, 'HasResultSet': True, 'Id': '61e30b26-8398-4aca-95d6-306ff1e7298e', 'QueryString': 'select * from demo.data_api_test', 'RedshiftPid': 1073872366, 'RedshiftQueryId': 4722, 'ResultRows': 10, 'ResultSize': 565, 'Status': 'FINISHED', 'UpdatedAt': datetime.datetime(2022, 10, 27, 15, 20, 10, 370000, tzinfo=tzlocal()), 'ResponseMetadata': {'RequestId': 'b3e73d62-984d-4695-acda-1a78d13447d7', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': 'b3e73d62-984d-4695-acda-1a78d13447d7', 'content-type': 'application/x-amz-json-1.1', 'content-length': '331', 'date': 'Thu, 27 Oct 2022 21:34:31 GMT'}, 'RetryAttempts': 0}}
The status is “FINISHED”, which means the query ran successfully against Redshift. The last piece is to get the test data back from the select query. To do that we use the get_statement_results() call:
{'ColumnMetadata': [{'isCaseSensitive': False, 'isCurrency': False, 'isSigned': True, 'label': 'data_api_test_id', 'length': 0, 'name': 'data_api_test_id', 'nullable': 0, 'precision': 10, 'scale': 0, 'schemaName': 'demo', 'tableName': 'data_api_test', 'typeName': 'int4'}, {'isCaseSensitive': False, 'isCurrency': False, 'isSigned': True, 'label': 'user_id', 'length': 0, 'name': 'user_id', 'nullable': 0, 'precision': 10, 'scale': 0, 'schemaName': 'demo', 'tableName': 'data_api_test', 'typeName': 'int4'}, {'isCaseSensitive': True, 'isCurrency': False, 'isSigned': False, 'label': 'user_name', 'length': 0, 'name': 'user_name', 'nullable': 1, 'precision': 64, 'scale': 0, 'schemaName': 'demo', 'tableName': 'data_api_test', 'typeName': 'varchar'}, {'isCaseSensitive': True, 'isCurrency': False, 'isSigned': False, 'label': 'region', 'length': 0, 'name': 'region', 'nullable': 1, 'precision': 32, 'scale': 0, 'schemaName': 'demo', 'tableName': 'data_api_test', 'typeName': 'varchar'}, {'isCaseSensitive': False, 'isCurrency': False, 'isSigned': False, 'label': 'request_timestamp', 'length': 0, 'name': 'request_timestamp', 'nullable': 1, 'precision': 29, 'scale': 6, 'schemaName': 'demo', 'tableName': 'data_api_test', 'typeName': 'timestamp'}], 'Records': [[{'longValue': 1}, {'longValue': 2948}, {'stringValue': 'demo_user'}, {'stringValue': 'us-east-1'}, {'stringValue': '2022-10-27 14:01:10'}], [{'longValue': 2}, {'longValue': 4832}, {'stringValue': 'testing123'}, {'stringValue': 'us-west-1'}, {'stringValue': '2022-10-27 14:01:10'}], [{'longValue': 3}, {'longValue': 2948}, {'stringValue': 'demo_user'}, {'stringValue': 'us-east-2'}, {'stringValue': '2022-10-27 14:01:10'}], [{'longValue': 4}, {'longValue': 5827}, {'stringValue': 'fake_user'}, {'stringValue': 'eu-west-2'}, {'stringValue': '2022-10-27 14:01:10'}], [{'longValue': 5}, {'longValue': 3453}, {'stringValue': 'test_user'}, {'stringValue': 'eu-west-2'}, {'stringValue': '2022-10-27 14:01:10'}], [{'longValue': 6}, {'longValue': 93452}, {'stringValue': 'foo'}, {'stringValue': 'us-west-2'}, {'stringValue': '2022-10-27 14:01:10'}], [{'longValue': 7}, {'longValue': 6234}, {'stringValue': 'bar'}, {'stringValue': 'us-east-2'}, {'stringValue': '2022-10-27 14:01:10'}], [{'longValue': 8}, {'longValue': 65048}, {'stringValue': 'test'}, {'stringValue': 'ap-east-1'}, {'stringValue': '2022-10-27 14:01:10'}], [{'longValue': 9}, {'longValue': 1234}, {'stringValue': 'fake'}, {'stringValue': 'af-south-1'}, {'stringValue': '2022-10-27 14:01:10'}], [{'longValue': 10}, {'longValue': 5436}, {'stringValue': 'user'}, {'stringValue': 'us-east-1'}, {'stringValue': '2022-10-27 14:01:10'}]], 'TotalNumRows': 10, 'ResponseMetadata': {'RequestId': '4ba7938f-1b4f-4ebb-a1c1-000b92fe7e28', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': '4ba7938f-1b4f-4ebb-a1c1-000b92fe7e28', 'content-type': 'application/x-amz-json-1.1', 'content-length': '2445', 'date': 'Thu, 27 Oct 2022 21:38:56 GMT'}, 'RetryAttempts': 0}}
Let’s unpack what’s in this API response. There are basically 3 main parts to this: 1. the ColumnMetadata, 2. the Records themselves and 3. metadata about the data returned from the query and response. The ColumnMetadata describes each column in the data set sequentially and in my opinion the only useful piece of it that you need to pick out is the name to get the column name of the table.
The Records are a bit more intimidating, but basically they are arrays of key value pairs that describe the data type of the field and the value in the data. For instance, this record from above is really just the first record from our test data set:
[[{'longValue': 1}, {'longValue': 2948}, {'stringValue': 'demo_user'}, {'stringValue': 'us-east-1'}, {'stringValue': '2022-10-27 14:01:10'}]

This response object is also of type dict, and you would have to write a parser to pull the data out of the response objects if needed, but essentially those are the main pieces you would need in order to interact with the data from the response.
That’s it for the short demo on using the Redshift Data API!